MAJOR INCIDENT RESPONSE – HOSTING

We have received the following RCA from OVH who are our PRIMARY cloud service provider:
OVH – Root Cause Analysis
Between December 9 2025 and December 10 2025 several public-cloud PCI projects were mistakenly suspended. The suspension triggered a cascade of operational issues: customers could not order new services, and existing instances were shelved. The root cause was a false-positive fraud-detection rule that incorrectly flagged the IP addresses used by affected customers.
Because the total sum of suspended projects were large—containing thousands of running instances—the restoration effort took several hours to days for our team to manually restore the instances.
To prevent recurrence, we have implemented an additional human-verification step for large-scale suspensions (PCINT-8052) and enhanced our fraud-detection scoring logic.
Having already outlined areas for improvement as part of our initial incident response, we would like to confirm what changes we have now made to our service offering and internal processes.
Communication
We have created a Service Status page on our website which will be linked to from our Home Page using a colour coded icon. In the event of a major incident this status link will be RED to attract attention to anyone visiting our website. We will use this page to provide information and updates about any service related incidents. There is an option on this page to subscribe to an email notification whenever a new incident or update has been posted.
In the event of a major incident, our phone system will now answer all calls and play a message advising all inbound callers that we are experiencing a major incident with directions to our service status page and that we are receiving a high number of calls, which may result in longer wait times.
We have also worked with OVH to improve the lines of communication that we have with them. As a result, we now have 24/7 direct telephone access to their infrastructure team.
Website
Any process that is not related to publishing our website has been moved to dedicated services, ensuring the availability of our website at all times.
Failover
The bottle neck that restricted the speed at which we could fail over instances has been removed. Our failover tests will now be to fail over 1000 instances to ensure that we are not just testing the process but also testing the capacity to fail over in scale.
We have also made a fundamental change. As of the 1st February 2026, any instances that are offline for 30 minutes, will now AUTO FAIL OVER. Previously, we opted for MANAGED FAILOVER due to IP authenticated SIP trunks needing to be updated. Given that we send an email confirming the new IP address once failover has occurred, we have now taken the view that this puts more control in our customers hands to affect a resolution, with no action required by us. This also ensures a close to seamless failover, for those customers using credential based SIP trunks, as these instances will continue to work without intervention from any party.
However, we have facilitated a method by which instances can have auto failover disabled via the customer portal on an instance by instance basis.
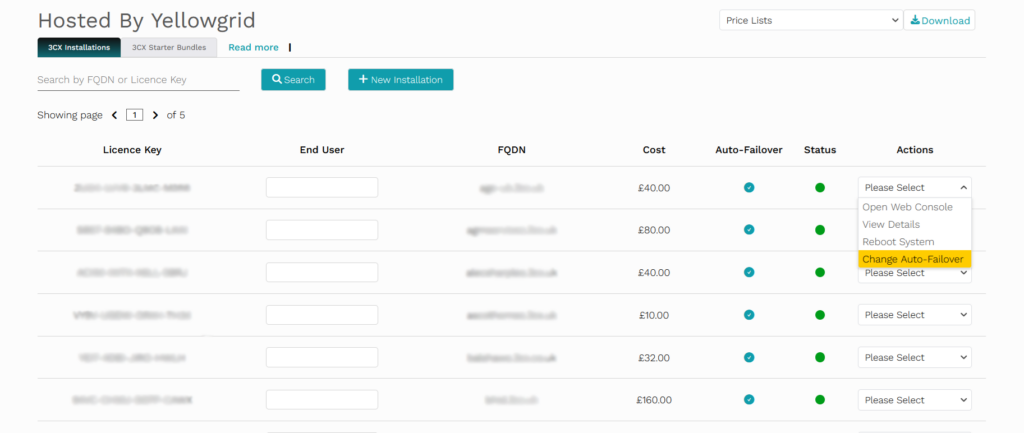
This might be an opportunity for those customers using our Standard SIP Trunks (IP Authenticated) to migrate to our Advanced SIP Trunks (Credential Based + FQDN Secured).
We monitor our instances every minute to determine whether the instance is available. Given that the 3CX FQDN can take up to 10 minutes to propagate (ENT=5 Mins, PRO=10 Mins) across the internet, failing over for short outages could create more downtime.
Therefore, our threshold for invoking failover is 30 minutes. Typically, it takes 10-15 minutes for the average instance to migrate. At which point an email is sent advising on the new 3CX IP address, then potentially up to 10 minutes for the 3CX FQDN to update.
Please note the following limitations to our DR solution:
Yellowgrid’s server IP addresses are required to be whitelisted in order to monitor availability, perform backups and to invoke DR as required. You will be notified if we lose access.
We can only fail over instances that are running supported versions of 3CX. The failed over instance will be running the latest 3CX version. The following versions are not supported:
•Alpha
•Beta
•Release Candidate
•End-of-life
Want a feel for our products? There are more videos available on our Yellowgrid YouTube Channel.
Reseller application – Click HERE to apply
Looking for more information? No problem, contact us on 03330144340 or sales@yellowgrid.co.uk.